Recent comments on posts in the blog:
I just finished my 5th project using Tapestry5 as a Java-Web-Framework.
I switched to Java/T5/Hibernate/Maven because i was just sick after 6 years of PHP/Symfony/Zend/Doctrine/YAML and typehinting via YAML.
Tapestry5 competes to most mayor web-frameworks and out-performs them with a lot of concurrency - read the details of T5 and some benchmarks.
Even though Java overtakes PHP on the wrong side - not by plain performance, but by overall-performance within complex sites (it's benchmarked).
I never had to restart a Server because of a memory-leak (okay, sometimes i just did not clean up which lead to crash/leak).
If you feel like Java is slow, compare bigger solutions - like Lucene/Zend-Search-Lucene/other Search-Servers.
Within a cluster, nothing compares to Hibernates 1st and 2nd level Cache.
Just updating some facts.
C correction:
include <stdio.h>
include <stdlib.h>
include <string.h>
include <time.h>
int main() { setbuf(stdout, NULL); //disable output buffering
char *str = malloc(9);
strcpy(str, "abcdefgh");
str = realloc(str, 8 + 8 + 1);
strcat(str, "efghefgh");
int str_len = strlen(str);
printf("%s", "exec.tm.sec\tstr.length\n");
time_t start = time(NULL);
char *gstr = malloc(1);
*gstr = '\0';
int gstr_len = 0;
int imax = 1024 / str_len * 1024 * 4;
int i = 0;
while (i++ < imax + 1000) {
gstr_len += str_len;
gstr = realloc(gstr, gstr_len + 1);
strcat(gstr, str);
char *pos = gstr;
while (pos = strstr(pos + 4, "efgh")) {
memcpy(pos, "____", 4);
}
if (gstr_len % (1024 * 256) == 0) {
printf("%lisec\t\t%dkb\n", time(NULL) - start, gstr_len / 1024);
}
}
}
C Benchmark:
exec.tm.sec str.length 0sec 256kb 1sec 512kb 3sec 768kb 5sec 1024kb 8sec 1280kb 12sec 1536kb 16sec 1792kb 22sec 2048kb 29sec 2304kb 38sec 2560kb 48sec 2816kb 60sec 3072kb 73sec 3328kb 89sec 3584kb 108sec 3840kb 129sec 4096kb
C++ correction:
include
include
include <time.h>
using namespace std;
int main() { string str("abcdefgh"); str += "efghefgh";
time_t start = time(NULL);
cout << "exec.tm.sec\tstr.length" << endl;
string gstr;
int imax = 1024 / str.length() * 1024 * 4;
int i = 0;
while (i++ < imax + 1000) {
gstr += str;
for (size_t pos = gstr.find("efgh");
pos != string::npos;
pos = gstr.find("efgh", pos + 4)) {
gstr.replace(pos, 4, "____");
}
if ((gstr.length() % (1024 * 256)) == 0) {
cout << time(NULL) - start << "sec\t\t" << gstr.length() / 1024 << "kb" << endl;
}
}
return 0;
}
C++ Benchmark:
exec.tm.sec str.length 2sec 256kb 9sec 512kb 21sec 768kb 37sec 1024kb 58sec 1280kb 83sec 1536kb 113sec 1792kb 148sec 2048kb 188sec 2304kb 232sec 2560kb 281sec 2816kb 335sec 3072kb 393sec 3328kb 457sec 3584kb 525sec 3840kb 598sec 4096kb
Perl Benchmark (for comparison):
exec.tm.sec str.length 2sec 256kb 6sec 512kb 14sec 768kb 24sec 1024kb 38sec 1280kb 54sec 1536kb 73sec 1792kb 96sec 2048kb 122sec 2304kb 150sec 2560kb 182sec 2816kb 218sec 3072kb 256sec 3328kb 298sec 3584kb 343sec 3840kb 391sec 4096kb
Hi!
Very nice post! It's good to have comparative data on so many languages in one place.
I have one suggestion: your speed graphs would really be more readable and easier to interpret if you plotted them in log-log scale. For starters, you would not need separate graphs for the slow and fast languages. But more importantly, some features of your data set would stand out so more clearly.
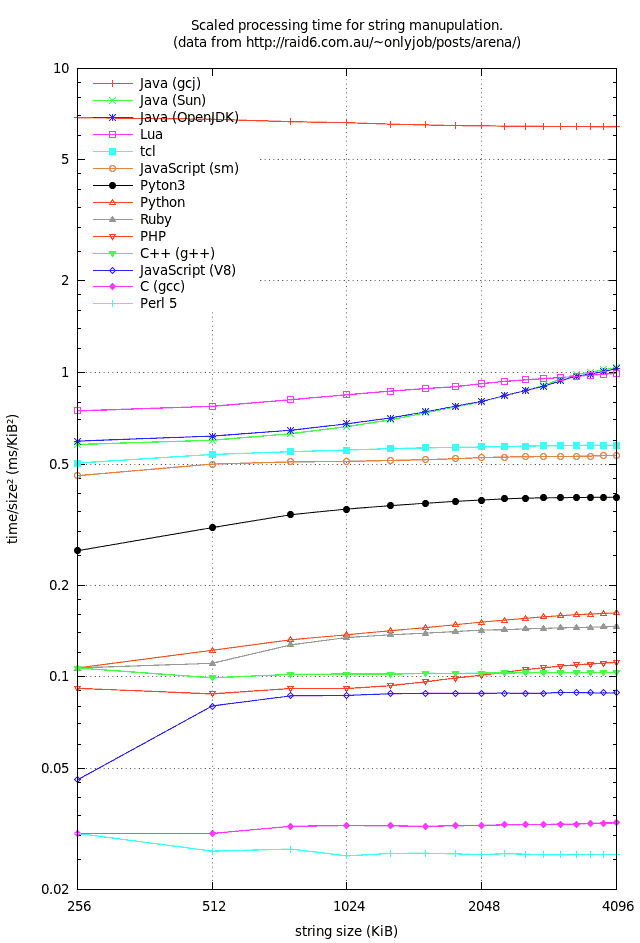
The most striking feature of such a log-log plot is that the influence of string length on execution time is very consistent across languages: every language gives a straight line in the plot, and all the lines are parallel! This is because the execution time scales as O(n²), where n is the size of the string, irrespective of the language. This is no big surprise, as that's what one would expect from examination of the algorithm you used for the test, but at least it shows that none of those languages is doing anything weird, like optimizing your code to O(n), or failing catastrophically to O(exp(n)).
Here is a plot of (time/size²) vs. size, base on your data: http://edgar-bonet.org/misc/lang-speeds.png
{kind=link}
Compared to a plain time vs. size plot, this plot emphasizes the differences between languages, as well as the deviations from a pure O(n²) law. Here one can see that most languages do actually very slightly worse than O(n²), while two of them (Java gcj and Perl 5) do slightly better.
Based on this plot, some of your conclusions could be reexamined:
Speed tests fall into 4 categories: [...]
Here your "Fastest" group is over-broad: there is a 6-fold performance gap between Python and Perl. On the other hand, you put tcl and Lua in different groups, although Lua is only 1.72 times slower than tcl. A better classification would probably be:
- Java gcj
- Java (Sun and OpenJDK), Lua, tcl, JavaScript (sm) and Python 3
- Python, Ruby, PHP, C++ and JavaScript (V8)
- C and Perl 5
All tested languages are good with manipulation of little strings but as the processed data grow the difference manifests itself.
On the contrary: your data clearly shows that not all languages are good at manipulating small strings. Actually, the performance spread for small strings (a factor 225 between fastest and slowest) is huge, and only marginally smaller than the spread for big strings (a factor 247).
performance of C and Perl5 is almost a flat line on graph indicating very little degradation. It means that C and Perl5 process increasing amount of data at (almost) constant speed.
C++, JavaScript (sm and also V8 beyond 768 KiB) and tcl also provide constant speed. Java on gcj even shows a slight speedup with longer strings! It goes from 6.88 to 6.43 ms/KiB². But obviously, constant speed does not mean good speed.
Some language's performance degrade faster than others so in beginning of this test Java somewhat 20 times slower than Perl5 and in the end Java is about 40 times slower (for same amount of data). Clearly this is an important characteristic - size matters!
Size matter barely. It is true that the curves are not strictly parallel, but deviations are small. And even though you can spot some crossings (like Lua outperforming the Javas beyond 3328 KiB, or C++ beating PHP beyond 2304 KiB), the languages that cross are of comparable speed on the whole range of tested sizes.
I realize this post sounds a little bit too critical of your study. That was not my intention. The main conclusions of your article (that string manipulations are an important performance metric, and the relative performances of the contenders) seem solid. Or at least, should I say, you convinced me. 
Regards,
Edgar.
Hi!
Sorry for my mistakes, I'm not a native speaker.
Being a Java/test automation developer, I was shocked to see the bad performance of Java! I started to debug and profile your code and finally I ended up with almost the same code that was already proposed by another Java-guy (I did not notice it at first).
Let me explain what's going on the background.
First and foremost, using pure strings instead of StringBuilder is not the main problem here - the Java compiler converts normal String concatenations to StringBuilder calls as an optimization technique (at least it did on my computer). The main issue is with the implementation of String/StringBuffer classes.
There is a class Matcher, which handles regular expression matching. When you call String.replaceAll(), in turn it calls Matcher.replaceAll(). In replaceAll(), a StringBuffer instance is used as a buffer. When the replace is done, the a String object is returned, so the contents of StringBuffer must be converted to String (returning the StringBuffer is not an option, because it does not extend String). So a new String instance is created - but the complete char[] array inside StringBuffer is deepcopied* with System.arrayCopy() every time you call replaceAll(), causing a huge performance hit on the memory subsystem!
That's why the StringBuilder.replace() is necessary to avoid moving big chunks of data between StringBuffer and String.
Also, note that the code above by the "brilliant Java developer" can be further optimized because once the string "efgh" is not found, the index must be calculated again with indexOf() which is an extremely costly operation (it uses the naive substring search algorithm instead of an efficient one, like Knutt-Morris-Pratt):
gstr.append(str);
int startIndx;
if (savedLastIndex == -1) {
startIndx = gstr.indexOf("efgh");
savedLastIndex = startIndx;
} else {
startIndx = gstr.indexOf("efgh", savedLastIndex);
savedLastIndex = startIndx;
}
while(startIndx != -1){
gstr.replace(startIndx, startIndx + 4, "____");
startIndx = gstr.indexOf("efgh", startIndx + 4);
}
If you save the index, it gives a huge performance boost:
exec.tm.sec str.length allocated memory:free memory:memory used
0 0 15872:15590:281
0sec 256kb 15872:12921:2950
0sec 512kb 15872:13284:2587
1sec 768kb 15872:11580:4291
1sec 1024kb 15872:10034:5837
2sec 1280kb 15872:3881:11990
2sec 1536kb 15872:6766:9105
3sec 1792kb 15872:5212:10660
3sec 2048kb 15872:3727:12144
4sec 2304kb 25156:11130:14025
4sec 2560kb 25156:9625:15530
4sec 2816kb 25156:8119:17036
5sec 3072kb 29316:15215:14100
5sec 3328kb 29316:13675:15640
6sec 3584kb 29316:12135:17180
I know it's almost like cheating... But this is the unfortunate effect of how Strings are handled in the platform library (not in the JVM!).
To all:
Thanks for your comments. Please remember this is not just about speed. Less than 30% of this article is about benchmark.
Re: comment 08:
Thanks for sample code. In the update to this article which you obviously missed, StringBuilder approach is discussed and tested. Even though it took the stress away from GC it, in my view it lose to other languages even more, performance wise. As I explained I believe math comparison is not convincing and very difficult to design.
In my everyday job I observe the same pattern of exponential slowdown on real Java web applications. It is starting with multiple HTTP requests which stresses GC enough to cripple 8 CPU server with more than 8 GiB of RAM. Backend doesn't do much string operations (if any) but whatever initialisation necessary for every new session is enough to provoke aggressive GC which utilise only one CPU when other 7 are waiting for GC to finish.
With GC quickly become bottleneck for most multi-threaded workload in Java. Ultimately it makes Java a single-user language - that's why it is not too bad on android but for web applications where more than one request is expected you won't find anything more miserable than Java no matter if strings operations are used or not.
Re: comment 09:
Yes my Java code sucks. However to me any Java code is like this - not beautiful to say the least.
Re: comment 10:
Applications in C# are facing potential patent threat from Microsoft. It just silly to work with C# unless you work with Windows which makes it double silly. If you're interested to compare C# at least you could contribute a sample code (or donation which would be more convincing).
Re: comment 11:
Thanks, very interesting about Susohin! To your knowledge Debian no longer ship PHP with Susohin by default.
Re: comment 12:
If you test with different compiler/interpreter version, which is likely the case given you tried about a year later, you can expect performance difference within 10%. I'm not sure if this match your definition of 'significally'. I have no explanation of poor C performance in my test. It could be related to default optimisations, not optimal for notebook processor or even performance regression of a particular compiler version. In this test I deliberately use defaults so I run test as simple as 'gcc c_test.c -o c_test' and then
./c_test | ./runtest.sh c_test c_test.data.txt
I just run C and Perl tests again on different machine (amd64; Linux kernel 3.2) with all recent updates and C completed the test in 271 sec. while Perl finished in 560 sec. (gcc 4.6.3; Perl v5.14.2). Please note that original testing for this article was done on notebook on 'i386' architecture. See particular compiler's versions in *.data.txt files.
Re: comment 13:
I never claimed that any Perl code is easy to read. My arguments have nothing to do with experience or bias. Poorly written Python code can be as hard to read as anything else.
Re: comment 15:
Your suggestion would be easier to understand if you provide a code example. Please do not assume all readers to be profoundly competent in Lua to understand what you're saying.
Re: comment 16:
Exactly! Methodology-wise it is also makes sense to compare code written pretty much alike. Java people argue for using very special workaround they can use for a particular case but it may be said that comparison would be unfair because sample code diverge more from other examples.
Re: comment 17:
Thanks, I didn't try your suggestion as I doubt it would affect test results. I verified the output produced by all code samples before testing so this minor flaw is unlikely to affect comparison in any way.
Re: comment 18:
I don't find your argument about read-only (aka immutable) strings convincing. You suggest to compare special case for Java to generic case for other languages. It has already been done in the update to this article and Java results were not as good in the context of other languages. It might be interesting to see how badly C results will be affected by changing realloc to malloc but Java GC is obviously stressed very much unless StringBuilder is used.
In multi-threaded applications Java is much worse than Python and other languages because GC is choking and freezing other threads.
Re: comment 20:
We already tried pretty much what you're suggesting in June 2011. I'm surprised how many commenting readers didn't read the whole article.
Re: comment 21 and 23:
I was seriously consider removing your comments. In the future I won't tolerate remarks worthless to other readers.
This article is especially useful for beginners because it demonstrate the consequence of sloppy Java coding and provide with possible solutions kindly contributed by readers. Java is very unforgiving and demanding - this is exactly the point of this article because it shows the amount of effort needed to make something barely working in Java comparing to other languages.
Maybe Java is not too bad for you, but hopefully others may get real about it.
Re: comment 24:
All the hard work is done by memstat provided by 'memstat' package. You can pipe the output of sample code to runtest.sh which takes two arguments: <executable to monitor> and <file name to save data>
The Java code used for this benchmark is too poor.
Only very unexperienced and uneducated Java Programmers would use code like that, sorry.
Try this code and see its results (I was forced to remove the division by 1000 when printing times).
What happened?
The original Java code relied on the + operator, but even basic books tell you that you should use a StringBuilder instance.
Another thing.
Exceptions are NOT "a fancy syntax for if-else", sorry that's an awful statement.
It may be hard to understand what an Exception is, sadly. But a method that declares an exception is warning the coder that "something may go wrong". The programmer may say "it is my code here that has to handle it" and write the try/catch block. Sometimes he may think "let the calling function handle the problem" and simply declare that his own code may trow an exception. Nevertheless has to stop and thing what to do when things go bad.
By the way, using try/catch instead of if/then is about ten thousand times slower...